Es muy común en el día a día encontrarse con bases de datos que cuentan con diferentes tipos de variables, ya sean numéricas, temporales, de texto o categóricas. Estas últimas son el tema de discusión de este post. El paquete inspectdf ofrece un conjunto de funciones que resultan particularmente útiles cuando lo que se busca es explorar el comportamiento de este tipo de variables.
El primer paso es tener debidamente instalado el paquete inspectdf.
library(devtools)
install_github("alastairrushworth/inspectdf")Una vez instalado es necesario cargarlo, así como cargar también el paquete dplyr, especialmente para poder usar el operador %>%.
library(inspectdf)
library(dplyr)Para este ejemplo se utilizará la base de datos starwars, la cual viene incluida en el paquete dplyr y que cuenta con datos de varios personajes de este universo cinematográfico.
starwars %>%
head()## # A tibble: 6 x 14
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 Luke~ 172 77 blond fair blue 19 male mascu~
## 2 C-3PO 167 75 <NA> gold yellow 112 none mascu~
## 3 R2-D2 96 32 <NA> white, bl~ red 33 none mascu~
## 4 Dart~ 202 136 none white yellow 41.9 male mascu~
## 5 Leia~ 150 49 brown light brown 19 fema~ femin~
## 6 Owen~ 178 120 brown, gr~ light blue 52 male mascu~
## # ... with 5 more variables: homeworld <chr>, species <chr>, films <list>,
## # vehicles <list>, starships <list>Análisis exploratorio de manera tabular
EL paquete inspectdf permite calcular algunos estadísticos descriptivos rápidamente para cualquier tipo de variable mediante la función inspect_types().
starwars %>%
inspect_types()## # A tibble: 4 x 4
## type cnt pcnt col_name
## <chr> <int> <dbl> <named list>
## 1 character 8 57.1 <chr [8]>
## 2 list 3 21.4 <chr [3]>
## 3 numeric 2 14.3 <chr [2]>
## 4 integer 1 7.14 <chr [1]>El resultado anterior muestra que hay 7 variables de tipo character, lo cual representa el 53.84% de la base de datos. Además, hay dos variables de tipo numérico, que representa un 15.38% del total. Lo anterior es útil para un primer vistazo, pero resulta interesante ir un poco más allá y describir más en detalle todas las variables. Para esto puede usarse la función inspect_cat().
starwars %>%
inspect_cat()## # A tibble: 8 x 5
## col_name cnt common common_pcnt levels
## <chr> <int> <chr> <dbl> <named list>
## 1 eye_color 15 brown 24.1 <tibble [15 x 3]>
## 2 gender 3 masculine 75.9 <tibble [3 x 3]>
## 3 hair_color 13 none 42.5 <tibble [13 x 3]>
## 4 homeworld 49 Naboo 12.6 <tibble [49 x 3]>
## 5 name 87 Ackbar 1.15 <tibble [87 x 3]>
## 6 sex 5 male 69.0 <tibble [5 x 3]>
## 7 skin_color 31 fair 19.5 <tibble [31 x 3]>
## 8 species 38 Human 40.2 <tibble [38 x 3]>La función inspect_cat() muestra en la primera columna el nombre de la variable, en la segunda la cantidad de valores únicos que contiene, es decir, la variable eye_color tiene 15 niveles diferentes, o lo que es lo mismo, hay 15 colores e ojos diferentes en la base de datos. La tercera columna muestra el valor más común que aparece en la variable, por ejemplo, la especie más común que aparece en la base de datos son los humanos. La cuarta columna indica el porcentaje que representa el nivel más común, por ejemplo, los ojos color café representan el 24.13% de todos los colores presentes en los datos. ¿Y qué representa la quinta columna? Pues es una lista con las proporciones de cada nivel de la variable. Para ejemplificar esto último, se asignará al objeto df el resultado anterior.
df <- starwars %>%
inspect_cat()
df$levels$eye_color## # A tibble: 15 x 3
## value prop cnt
## <chr> <dbl> <int>
## 1 brown 0.241 21
## 2 blue 0.218 19
## 3 yellow 0.126 11
## 4 black 0.115 10
## 5 orange 0.0920 8
## 6 red 0.0575 5
## 7 hazel 0.0345 3
## 8 unknown 0.0345 3
## 9 blue-gray 0.0115 1
## 10 dark 0.0115 1
## 11 gold 0.0115 1
## 12 green, yellow 0.0115 1
## 13 pink 0.0115 1
## 14 red, blue 0.0115 1
## 15 white 0.0115 1La tabla anterior muestra la proporción de cada color de ojos. Esto mismo se aplica a cualquiera de las otras variables.
Análisis exploratorio de manera gráfica
En algunas ocasiones los valores numéricos no sean tan claros ni fáciles de interpretar, ya sea por a cantidad de datos o bien por cuestiones de comodidad. El paquete inspectdf también permite hacer análisis exploratorio de manera gráfica
df %>%
show_plot()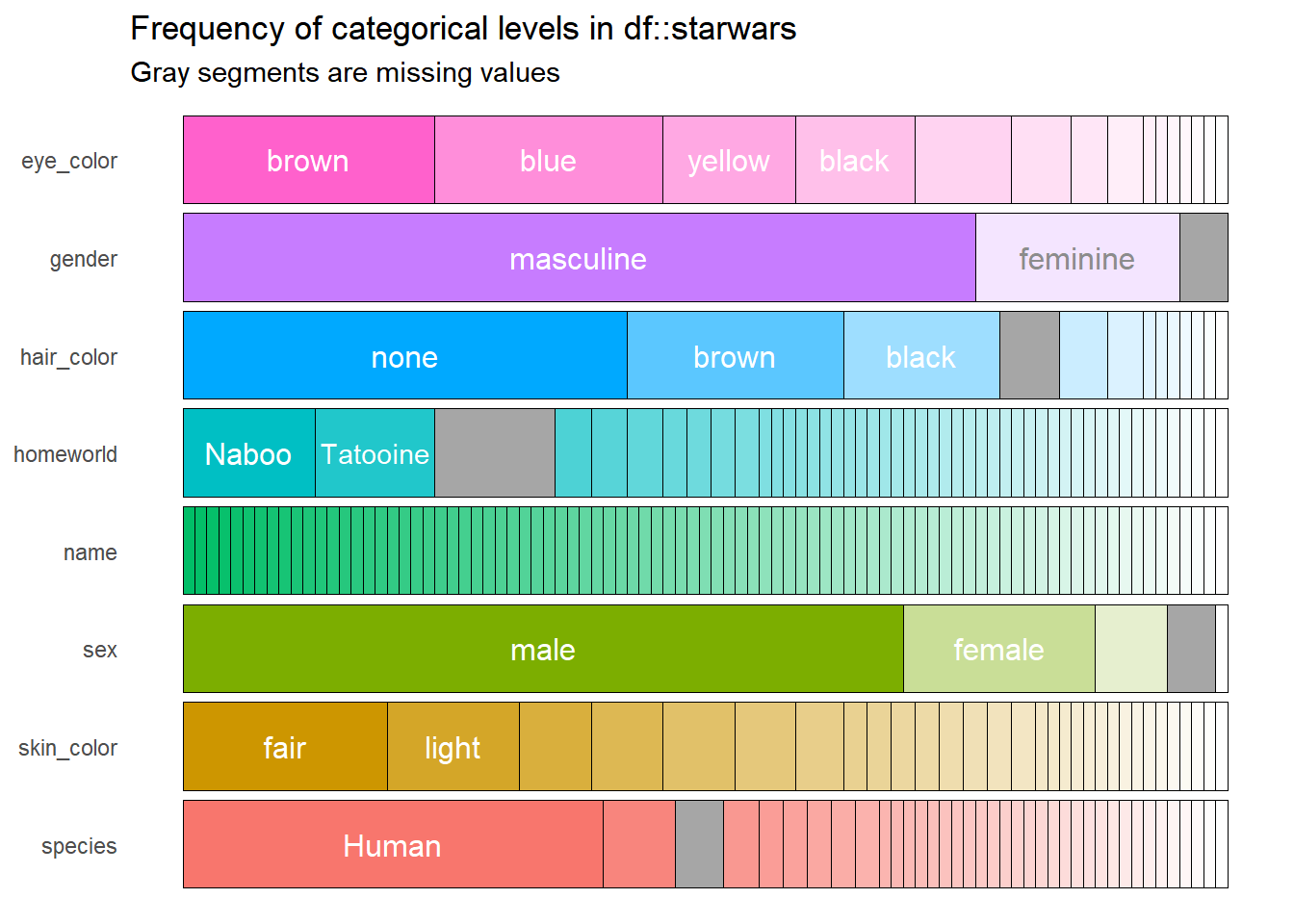
Este resultado contiene la misma información que el objeto df, pero ahora es más fácil, rápido e incluso agradable para interpretar. Sin embargo, este resultado puede mejorar, pues por ejemplo la variable name no sirve de mucho en el gráfico porque todos los nombres son diferentes. Esto se puede solucionar modificando el argumento high_cardinality, lo cual hace que únicamente se grafiquen todas aquellas categorías que aparezcan un determinado número de veces, digamos cuatro.
df %>%
show_plot(high_cardinality = 4)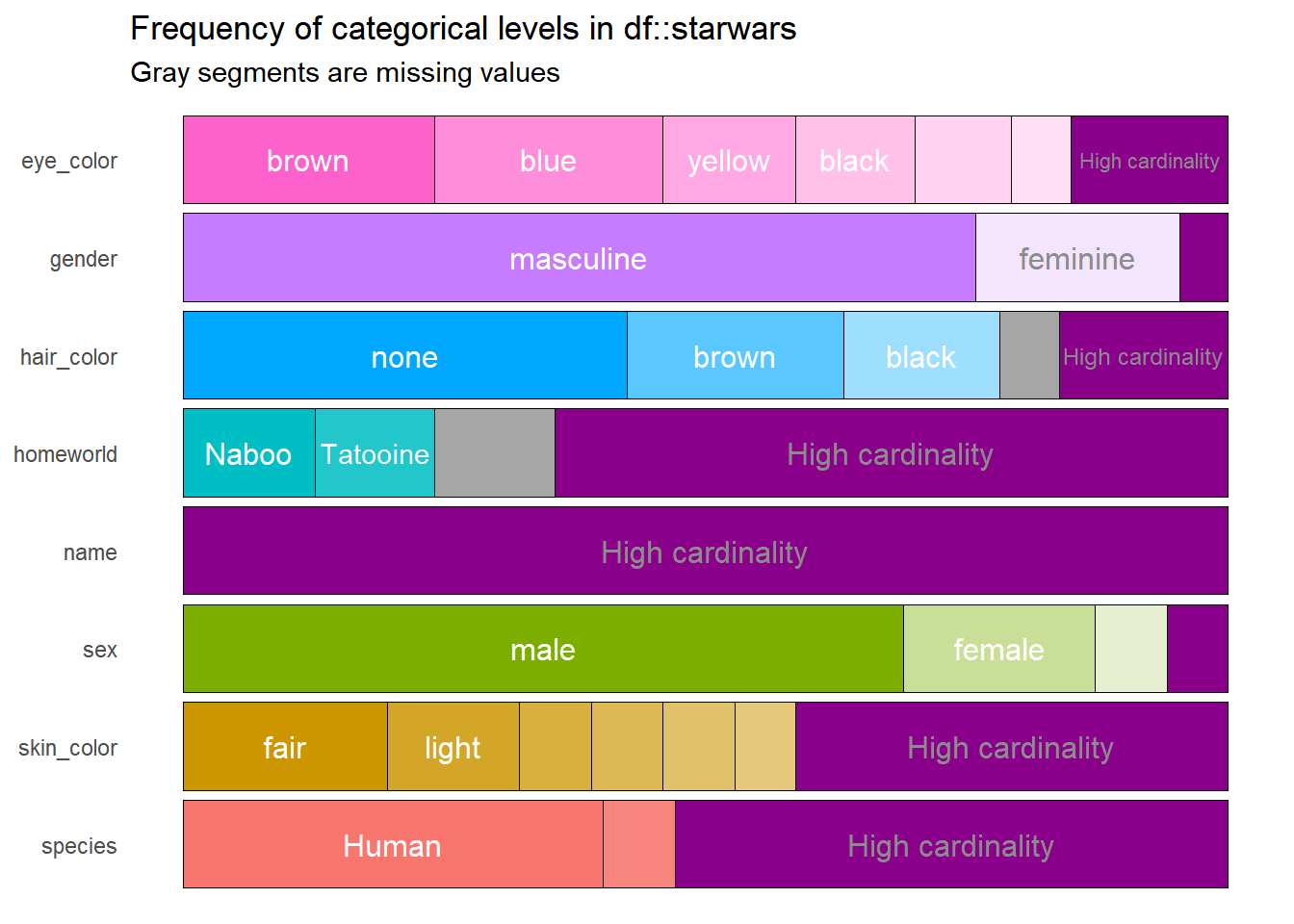
Finalmente, si los colores no resultan del todo agradables, pueden manipularse a voluntad mediante las 5 paletas de colores que ofrece el paquete y que e el futuro serán más, basta modificar el argumento col_palette con los números entre uno y cinco para lograr esto.
df %>%
show_plot(high_cardinality = 4, col_palette = 4)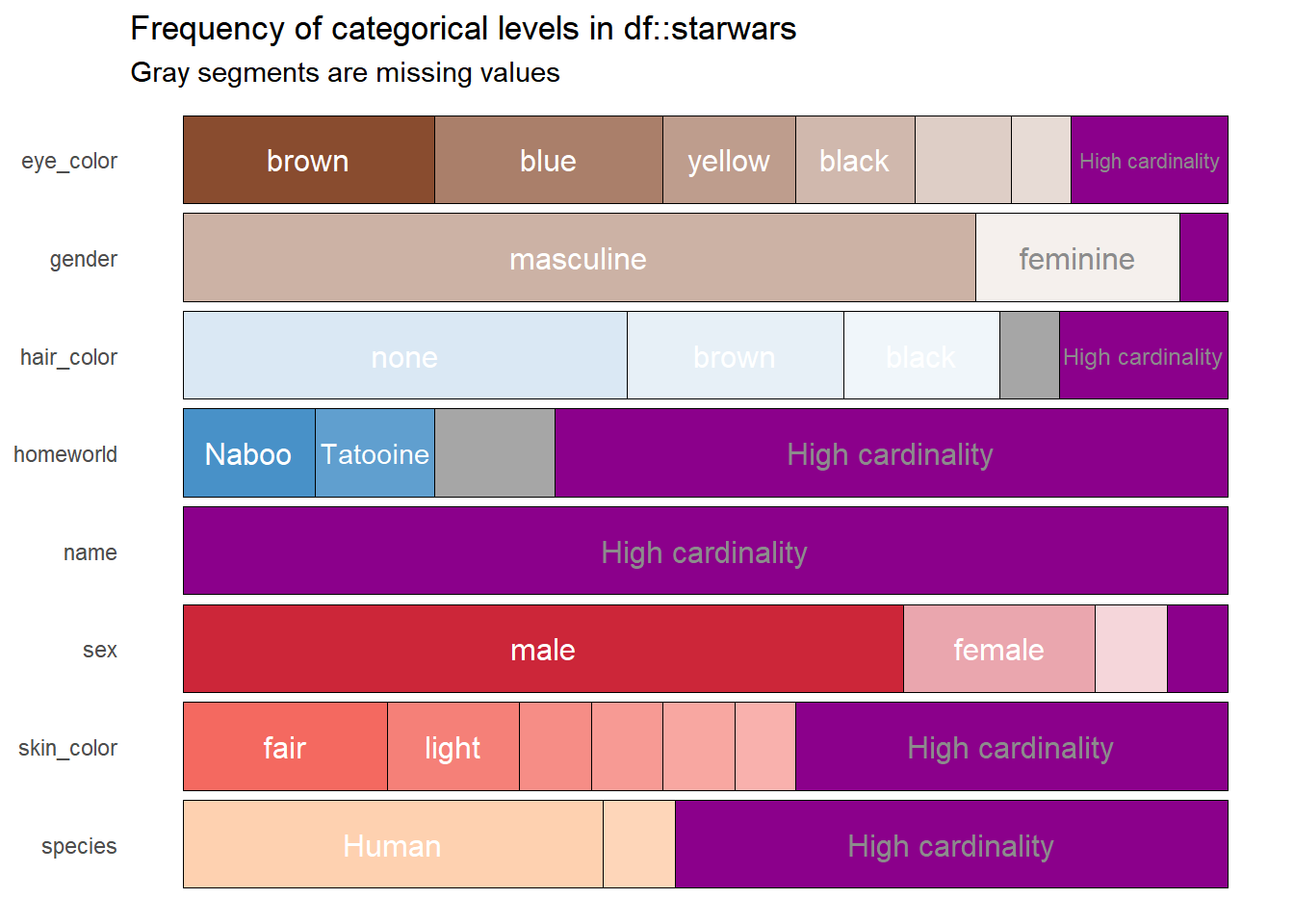
df %>%
show_plot(high_cardinality = 4, col_palette = 5)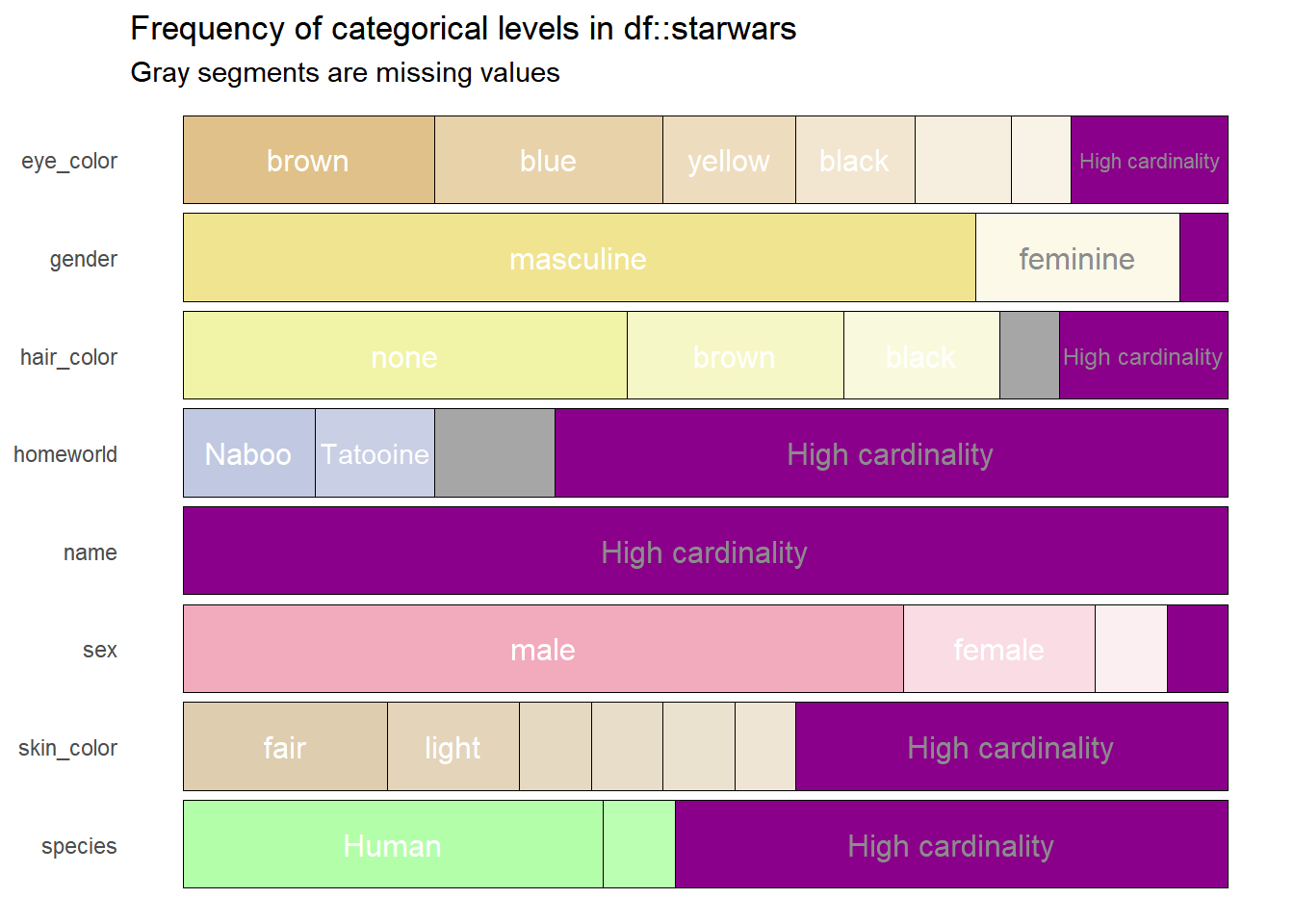
 https://orcid.org/0000-0001-6733-4759
https://orcid.org/0000-0001-6733-4759